从size-512内存泄露看slab分配
又一次开始土法炼钢了,测试部发现很多环境panic了,从黑匣子看到的信息是OOM了,虽然kill掉了占用比最大的进程,但是监控进程发现后reboot了单板。然后把meminfo收集到的信息,对比发现,slab增长的非常快,发现task_struct占用了很多,通过硬件中断和jprobe挂钩子发现是一个驱动访问所有进程的atomic_t usage,调用get_task_struct但没有put_task_struct释放usage,导致进行大量线程申请的时候不能自动释放,slab中的task_struct大量增加不释放。
具体代码如下:
static inline void put_task_struct(struct task_struct *t)
{
if (atomic_dec_and_test(&t->usage))
__put_task_struct(t);
}
前面这些都是前奏,解决问题后,测试部重新测试,仍发现有内存增长,拿来看发现task_struct增长的问题解决了,但size-512在大量增长。只好接着上jprobe抓取调用栈,把钩子挂到了slab分配函数kmem_cache_alloc,通过cachep->name过滤size-512打印调用栈,结果是直接将内核打爆了。
接着回头到/proc/slabinfo找线索,slab的增长体现在两个参数上,num_objs和num_slabs,num_objs是slab分配的对象个数,而num_slabs则是分配的slab个数,每个slab占用一个4K页。因为num_slab增长的较低,思考在这上面挂钩子处理,就要了解slab具体的分配机制。
slab本身是一种内存管理方法,更直接的概念是,它就是类似内存池的东西,由于内核进行大量的小内存(B级别)分配,如果每次都申请内存,进程延迟就非常厉害,那么就用内存池的方式提前分配好对应数据结构的内存,申请者只需要到内存池里面拿到对应指针即可。只是对应的每个内存池一般都是几个内存页的大小。
已size-512举例,size-512本身是内核申请通用的结构体(或者理解成内核slab没有特别标注的少数派),称为对象(obj),结构体大小在256~512B之间,所以通用slab本身存在内部碎片。那么一个内存页4K大小,可以容纳8个obj,那么预分配内存,初始化内存池的时候,此时称为slabs_empty,此时/proc/slabinfo中num_slab++;如果系统只需要申请一个obj,就会空闲7个obj,此时称为slabs_partial,此时/proc/slabinfo中num_objs++;如果系统又申请8个obj,原slab全部分配不够用,称为slabs_full,重新申请slab 4K,那么num_slab++。需要留意的是,slab obj所谓的释放,也只是将相关指针置空,并不将申请的物理内存释放,而且由于obj在内核中基本都是高频使用的,不释放的有很高复用率,对于内存申请有很高的效率。只有当drop_cache内存紧张的时候,slabs_empty才会被释放物理内存。
下面说一下slab的具体组织形式
struct kmem_cache {
/* 1) per-cpu data, touched during every alloc/free */struct array_cache *array[NR_CPUS];
/* 2) Cache tunables. Protected by cache_chain_mutex */unsigned int batchcount;
unsigned int limit;
unsigned int shared;
unsigned int buffer_size;
u32 reciprocal_buffer_size;
/* 3) touched by every alloc & free from the backend */
unsigned int flags;/* constant flags */unsigned int num;/* # of objs per slab */
/* 4) cache_grow/shrink *//* order of pgs per slab (2^n) */unsigned int gfporder;
/* force GFP flags, e.g. GFP_DMA */gfp_t gfpflags;
size_t colour;/* cache colouring range */unsigned int colour_off;/* colour offset */struct kmem_cache *slabp_cache;
unsigned int slab_size;
unsigned int dflags;/* dynamic flags */
/* constructor func */void (*ctor)(void *obj);
/* 5) cache creation/removal */const char *name;
struct list_head next;
/* 6) statistics *//*
* We put nodelists[] at the end of kmem_cache, because we want to size
* this array to nr_node_ids slots instead of MAX_NUMNODES
* (see kmem_cache_init())
* We still use [MAX_NUMNODES] and not [1] or [0] because cache_cache
* is statically defined, so we reserve the max number of nodes.
*/struct kmem_list3 *nodelists[MAX_NUMNODES];
/*
* Do not add fields after nodelists[]
*/};
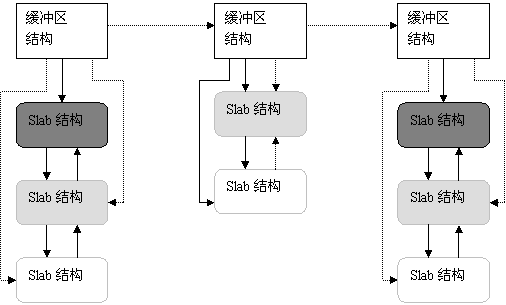
name就是slab obj的名字,如size-512;next指向下一个slab类型,如task_struct;kmem_list3则是slab的三个链表,即
struct kmem_list3 {
struct list_head slabs_partial;/* partial list first, better asm code */struct list_head slabs_full;
struct list_head slabs_free;
unsigned long free_objects;
unsigned int free_limit;
unsigned int colour_next;/* Per-node cache coloring */spinlock_t list_lock;
struct array_cache *shared;/* shared per node */struct array_cache **alien;/* on other nodes */unsigned long next_reap;/* updated without locking */int free_touched;/* updated without locking */};那么就可轻易看到slab的组织形式如下:
下面继续看问题,从上了解到监控num_slab的打印估计比监控num_objs少上7倍,决定在num_slab上挂钩子。
排查代码发现,obj通过kmem_cache_alloc函数申请,通过__cache_alloc >> __do_cache_alloc >> ____cache_alloc依次进入到正题,通过PER_CPU变量array,传递给ac_get_obj获取obj,如果obj没有获取到,此时是array cache中获取不到obj了,则通过cache_alloc_refill重新分配slab到array cache,cache_alloc_refill遍历kmem_list3中半满和空闲链表,发现都没有节点可以供
分配,则必须进行slab内存重新申请物理内存。
if (entry == &l3->slabs_partial) {
l3->free_touched = 1;
entry = l3->slabs_free.next;
if (entry == &l3->slabs_free)
goto must_grow;
}slab重新申请内存由cache_grow完成,具体交给kmem_getpages处理,那么挂钩子就在kmem_getpages上,没有export,只能通过kallsyms_lookup_name函数获取函数地址。
此时调用栈打印出来了,绝大部分都是相同的一个栈,但排查了一下,对应的A函数根本没有内存泄露,百思不得其解中,经过同事提醒,才发觉A函数会高频申请obj,而隐藏的泄露函数B的频率较低,每次B申请size-512都是obj供给,而A则很多次都没有命中slab,则kmem_getpages抓取的都是A函数。
只好还是回头抓取kmem_cache_alloc,手动降低打印频率,和kmem_cache_free对比看,才发现了问题点,ipmi的一个驱动有内存泄露,原来用户态的一个C进程每次都通过ipmi发消息给D端,而D端有个低概率的问题导致返回报文超长,C通过ipmi算出报文异常,则不接受,该异常报文则存储在内存中,仍排在ipmi消息队列前面,后面仍有报文来临,C仍取第一个异常报文,导致所有返回报文阻塞在ipmi侧,体现为ipmi内存泄露。
修改方法则是解决D的bug,将C设置为截断获取报文的方式。
另外谈内存泄露,加上自己的一些土方法,在meminfo中,有效使用的物理内存=total-free-buffer-cache,虽然不完全准确,也可以此判断内存泄露情况,如果匿名页增长,则对比ps看哪进程RSS占用高,slab变化大,则要看哪一个slab变化大,然后用jprobe等三八大盖解决,当然,有条件的还是用美式武器kmemcheck搞定。
总结一下对jprobe等工具的使用感想:
抄袭一下初中课本的一段,福特汽车公司的一台马达发生故障,怎么也修不好,只好请一个叫斯坦曼的人来修。他看了一会,指着电机的某处说:“这儿的线圈多了16圈。”果然,把16圈线去掉后,电机马上运转正常。福特公司经理问斯坦门茨要多少酬金,斯坦门茨说:“1万美元。”1万美元?就只简简单单画了一条线!斯坦门茨看大家迷惑不解,转身开了个清单:画一条线,1美元;知道在哪儿画线,9999美元。福特公司经理看了之后,不仅照价付酬,还邀请斯坦曼到自己公司来。
工具就是划线而已,真正的价值在于知道在哪里划线。
从size-512内存泄露看slab分配来自于OenHan
链接为:https://oenhan.com/size-512-slab-kmalloc