journal block device代码分析
进入此门的肯定都对journal block device有一定了解,需要对ext3文件系统有了解,多余的就不赘述。
为什么要设计JBD?
普通数据是存在硬盘上的,文件系统也是作为普通数据存在硬盘上,类似如果碰到突然断电的情况,硬盘就可能损坏,硬件损坏,还是要硬件设计保证,软件设计(JBD)就是解决软件错误,断电可能会导致软件错误,举个例子,文件系统相当于常用的压缩文件,普通数据则是其中一个txt中的文字,如果压缩到一半被杀掉,如果txt中的文字损坏,压缩文件仍能解压,只是txt内容不同而已,但如果压缩文件的结构被损坏,很可能解压不来任何文件。而JBD就是防止文件系统的结构数据(元数据)被损坏,它作为一个缓存块先缓存所有的元数据,如果磁盘数据异常后,就从缓存块中恢复。
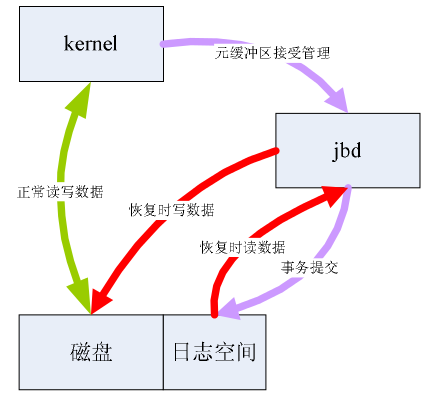
JBD的具体工作流程:
如上图示,kernel正常读写磁盘,读磁盘直接获取,写磁盘则走两条路,每个IO群(即事务),先写到jbd里面,然后在写磁盘,如果写磁盘被中断,则从jbd恢复,如果jbd被中断,OK,没影响。jbd本身数据存储到磁盘的一个用户态不可见位置,即日志空间,日志空间本身是一个文件系统结构的存储空间,有超级块,组描述符,位图等,估计所有数据系统都是类似结构。
基本原理就不说了,下面就以ext3_mkdir为例,描述jbd工作机制。
首先通过ext3_journal_start获取原子操作handle,(原子操作即操作不可分割的,只有完成态和未开始状态,不会停留在中间态,和atomic_inc不同,atomic加减是限制多线程冲突,handle则是保证完整性),具体细节可以参考ext3_journal_start函数,我对此的理解是,ext3_journal_start对handle进行了初始化,获取当前journal空间的数据,比如,空闲字节的开始位置。
handle = ext3_journal_start(dir, EXT3_DATA_TRANS_BLOCKS(dir->i_sb) + EXT3_INDEX_EXTRA_TRANS_BLOCKS + 3 + EXT3_MAXQUOTAS_INIT_BLOCKS(dir->i_sb));
在后面ext3_new_inode函数中见handle传递进入,在ext3_new_inode中申请新inode,需要修改位图,当然还有超级块和组描述符等,下面截取位图的写入作为一个描述:
bitmap_bh = read_inode_bitmap(sb, group);
if (!bitmap_bh)
goto fail;
ino = 0;
repeat_in_this_group:
ino = ext3_find_next_zero_bit((unsigned long *)
bitmap_bh->b_data, EXT3_INODES_PER_GROUP(sb), ino);
if (ino < EXT3_INODES_PER_GROUP(sb)) {
BUFFER_TRACE(bitmap_bh, "get_write_access");
err = ext3_journal_get_write_access(handle, bitmap_bh);
if (err)
goto fail;
if (!ext3_set_bit_atomic(sb_bgl_lock(sbi, group),
ino, bitmap_bh->b_data)) {
/* we won it */BUFFER_TRACE(bitmap_bh,
"call ext3_journal_dirty_metadata");
err = ext3_journal_dirty_metadata(handle,
bitmap_bh);
if (err)
goto fail;
goto got;
}
通过read_inode_bitmap获取位图数据bitmap_bh,用ext3_find_next_zero_bit算出空闲ino位置,用ext3_journal_get_write_access获取日志的写权限,更多的是将handle加入事务transaction管理,或者说将bitmap_bh加入到journal管理中,然后才开始进行具体的数据修改,也就是ext3_set_bit_atomic修改位图,修改完成使用ext3_journal_dirty_metadata标记为脏,即告诉journal本次handle操作结束,可以进行提交了。
ext3_new_inode下的组描述符也是类似,包括后面的目录项修改都是如此,也不赘述了。
需要提到的是,此处标记为脏的是元数据,非元数据使用ext3_journal_dirty_data函数,在ext3里面,如果发现当前数据是脏页,则直接进行刷新到磁盘,原因在注释中有描述。
/*
* This buffer may be undergoing writeout in commit. We
* can't return from here and let the caller dirty it
* again because that can cause the write-out loop in
* commit to never terminate.
*/if (buffer_dirty(bh)) {
get_bh(bh);
spin_unlock(&journal->j_list_lock);
jbd_unlock_bh_state(bh);
need_brelse = 1;
sync_dirty_buffer(bh);
jbd_lock_bh_state(bh);
spin_lock(&journal->j_list_lock);
/* Since we dropped the lock... */if (!buffer_mapped(bh)) {
JBUFFER_TRACE(jh, "buffer got unmapped");
goto no_journal;
}
/* The buffer may become locked again at any
time if it is redirtied */}
至此,一个使用journal的标准写入过程结束,后续的就是提交了。
jbd有常驻线程kjournald负责提交transaction,kjournald线程每个ext系列的分区分一个,主要部分通过调用journal_commit_transaction完成。需要插播一下,如果编译内核的时候打开CONFIG_JBD_DEBUG或者CONFIG_JBD2_DEBUG开关,就可以根据jbd-debug跟踪jbd的执行过程,有更直接的感觉,在代码实现上就是jbd_debug函数。
具体流程我建议打开debug开关后,对比着看,具体代码不梳理了,直接上图:

jbd前面所有设计都是为了此时的提交,需要留意的是此时设计的普通数据在元数据前进行提交,来保证ordered执行顺序。另外在之前写文件流程中提到ext3_ordered_write_end,中调用walk_page_buffers中journal_dirty_data_fn标记普通数据为脏,会将已脏的数据先用sync_dirty_buffer刷磁盘一下,可以对比参看。
最后则是出问题之后日志进行恢复:
journal恢复是在mount挂载磁盘的时候,ext3_fill_super()一直调用到journal_recover,判断是否进行日志恢复也是如下判断。
if (!sb->s_start) {
jbd_debug(1, "No recovery required, last transaction %dn",
be32_to_cpu(sb->s_sequence));
journal->j_transaction_sequence = be32_to_cpu(sb->s_sequence) + 1;
return 0;
}即根据日志的超级块s_start参数是否为0判断。
整个恢复过程有3部分组成,都是调用do_one_pass,只是传参不同,第一步获取recovery_info信息,journal的起点和终点,journal是一个循环利用的环状存储介质。第二步获取REVOKE块,第三步PASS_REPLAY则根据描述符块将日志信息写到磁盘上。
另外提一下在工作中碰到一个案例:内核在写文件的时候发生了多次复位,根据内核黑匣子记录的信息,看到journal_bmap获取信息为0,日志被__journal_abort_soft中断 了,再写journal出现了panic。当时看以为bmap出现异常,中间读取有问题,后来把journal日志块倒出来看,对应的一个间接索引块里面全为0,在普通文件中是正常的,称为文件的洞,而日志则是格式化一开始就全分配了,而且顺序读取利用不应产生文件的洞。具体原因再也没找到,但是发现fsck不支持修改journal出现洞的问题,导致重复复位,后来找到社区高版本fsck比对一下,改了一个补丁,勉强算解决了问题。
以上都是开胃小菜,更多的请读代码,文章描述不细致的地方请参考jdb代码分析
journal block device代码分析来自于OenHan
链接为:https://oenhan.com/ext3-jbd-journal
在data=ordered情况下,是文件数据先被写入,然后写入日志,此时日志包含了新文件的元数据, 然后提交日志,最后,如果是 delay allocate,过短时间真正的元数据才被写到磁盘上。
我的理解
请问一下,脏的元数据是什么刷新到磁盘的?
@JET 脏的元数据有两部分,journal的部分由journal_write_metadata_buffer构建了new_jh。
wbuf[bufs++] = jh2bh(new_jh)
struct buffer_head *bh = wbuf[i];
bh->b_end_io = journal_end_buffer_io_sync;
_submit_bh(write_op, bh, 1 << BIO_SNAP_STABLE); 也就是journal部分立即提交给了bio调度层。 文件系统的元数据部分的及时性此刻要求就没有了,可以交给系统进行刷新。
@OENHAN 这里的意思是说journal每次操作后都会提交一次bio那这个bio是异步还是同步的?
还有ext3文件的fsync操作具体是怎样做的?
我理解是先将journal flush到盘上,然后再对对应的每个记录分别更新对应位置的元数据(假设只journal元数据),是这样的吗?
谢谢!
@ARTHUR 先将journal flush到盘上,然后再对对应的每个记录分别更新对应位置的元数据,是这样的