Oprofile:CPU性能分析工具指南
在平台升级中经常碰到自测时性能指标没有问题,而平台转到产品业务部门匹配测试时就出了问题.如果是功能异常的问题,一般还是很好处理的,但如果碰到系统的性能问题,如CPU升高,内存使用超标,就比较不好搞了,老虎吞天,没有目标,一个版本几十万行代码一行行看,绝对能累死,尤其是内核组.
幸好开源界的风气好,提供了各种工具,本文主要介绍Oprofile工具,适用系统的CPU性能分析,最主要它能深入内核函数,这是很多用户态工具达不到的地方.
一、基本原理
根据CPU架构采样的触发有两种模式:
1) NMI模式: 利用处理器的performance counter功能, 指定counter的类型type和累进数量count. 比如
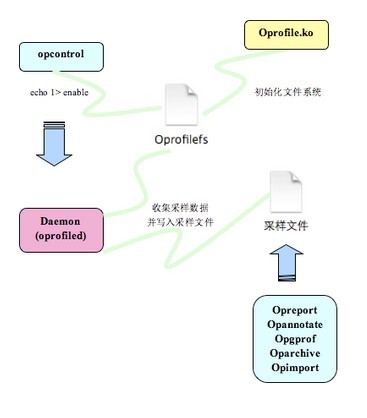
type=DTLB_MISS, count=500, 代表"Data TLB miss"每发生500次, 会触发一次中断. Oprofile.ko模块会相应这个中断, 然后看当前正在执行的是什么指令,那个函数, 那个模块(或者app, lib), 并进行计数. 不同的处理器支持的counter类型和count取值范围各不相同. 可以通过ophelp来查看当前cpu所支持的counter类型和参数. 例如, "--event=MISALIGN_MEM_REF:1000:0:1:0"表示非对齐的内存访问, 每1000次触发一个中断, 1000后面的0表示改特定counter的mask, 具体含义看ophelp的内容; 最后的1:0表示只对kernel采样, 不对用户空间程序采样. "--event=CPU_CLK_UNHALTED:10000:0:1:0"代表cpu时钟周期事件.每10000个cycle触发一次中断. "--event=L1I_MISSES:500:0:1:0"表示一级指令缓存的cache miss.
2) Timer Interrupt模式: 在没有performance counter支持的情况下(例如Vmware虚拟机下), 可以利用时钟中断来采样. 这时候就没有performance counter的概念了. 或者可以当成近似的cpu时钟周期事件. 要使用timer interrupt模式, 需要在加载oprofile.ko模块的时候,传递"timer=1"参数. modprobe oprofile timer=1
二、快速操作
1.首先要安装了Oprofile,具体版本适用不同,请自行Google
2.准备获取有debuginfo信息的内核文件vmlinux,具体方法请点入链接,这个vmlinux应该是用和环境内核完全一致的代码编译出来的
3.初始化oprofile,可以通过demsg查看oprofile使用的是哪一种模式:
oen@oen /tmp $ sudo opcontrol --init oen@oen /tmp $ dmesg | tail -n 1 [32197.736534] oprofile: using NMI interrupt.
4.开始获取CPU采样
oen@oen /tmp $ sudo opcontrol --start --vmlinux=/tmp/vmlinux ATTENTION: Use of opcontrol is discouraged. Please see the man page for operf. Using default event: CPU_CLK_UNHALTED:100000:0:1:1 Using 2.6+ OProfile kernel interface. Reading module info. Using log file /var/lib/oprofile/samples/oprofiled.log Daemon started. Profiler running.
5.这个时候启动需要监控的程序,如果是内核,就直接sleep一段时间即可
6.停止采样
oen@oen /tmp $ sudo opcontrol --stop Stopping profiling.
7.获取采样信息
oen@oen /tmp $ opreport -l CPU: Intel Ivy Bridge microarchitecture, speed 2.501e+06 MHz (estimated) Counted CPU_CLK_UNHALTED events (Clock cycles when not halted) with a unit mask of 0x00 (No unit mask) count 100000 samples % image name app name symbol name 459479 30.4134 chrome chrome /opt/google/chrome/chrome 88167 5.8359 libpepflashplayer.so libpepflashplayer.so /opt/google/chrome/PepperFlash/libpepflashplayer.so 61784 4.0895 libc-2.15.so libc-2.15.so /lib/x86_64-linux-gnu/libc-2.15.so 59765 3.9559 oprofile oprofile /oprofile 46383 3.0701 vmlinux vmlinux fb_deferred_io_fault 36778 2.4344 libglib-2.0.so.0.3400.1 libglib-2.0.so.0.3400.1 /lib/x86_64-linux-gnu/libglib-2.0.so.0.3400.1 31214 2.0661 vmlinux vmlinux native_read_tsc
这个样子就可以获取系统的CPU主要耗费在哪个函数上了,从上面的示例可以看到内核CPU主要在fb_deferred_io_fault和native_read_tsc函数上,就可对症下药,缩小问题排查范围。
oprofile还有很多参数,包括事件采样的配置等直接参考man手册吧。
关于oprofile代码调优的文章推荐阅读:
用 OProfile 彻底了解性能
Oprofile:CPU性能分析工具指南来自于OenHan
链接为:https://oenhan.com/oprofile-cpu-analysis
你好,我最近用到OProfile,网上搜索到你的文章,但无力自己编译vmlinux。不知道是否你能分享一份。我的邮箱是:[email protected]
谢谢了。
@water 每个发行版的内核版本不一样,但基本编译过程是大同小异的,无力自己编译指的是什么,具体编译过程可以参考ubuntu编译linux内核
我用的也是ubuntu,内核版本和你提到的linux_3.5.0是一样的,只是安装了ubuntu的安全更新。主要我的机器太老了,可能编译会花很长时间。E2160的CPU。
@water 你到百度网盘下载:http://pan.baidu.com/s/1eQl87qa
谢谢分享。Linux包很多很有意思。