Linux进程组调度机制分析
又碰到一个神奇的进程调度问题,在系统重启过程中,发现系统挂住了,过了30s后才重新复位,真正系统复位的原因是硬件看门狗重启的系统,而非原来正常的reboot流程。硬件狗记录的复位时间,将不喂狗的时间向前推30s分析串口记录日志,当时的日志就打印了一句话:“sched: RT throttling activated”。
从linux-3.0.101-0.7.17版本内核代码中可以看出,sched_rt_runtime_exceeded打印了这句话。在内核进程组调度过程中,实时进程调度受rt_rq->rt_throttled 的限制,下面便具体说一下涉及到的linux中进程组调度机制。
进程组调度机制
组调度是cgroup里面的概念,指将N个进程视为一个整体,参与系统中的调度过程,具体体现在示例中:A任务有8个进程或线程,B任务有2个进程或线程,仍然有其他的进程或线程存在,就需要控制A任务的CPU占用率不高于40%,B任务的CPU占用率不高于40%,其他任务占用率不少于20%,那么就有对cgroup阀值的设置,cgroup A设置为200,cgroup B设置为200,其他任务默认为100,如此便实现了CPU控制的功能。
在内核中,进程组由task_group进行管理,其中涉及的内容很多都是cgroup控制机制 ,另外开辟单元在写,此处指重点描述组调度的部分,具体见如下注释。
struct task_group {
struct cgroup_subsys_state css;
//下面是普通进程调度使用
#ifdef CONFIG_FAIR_GROUP_SCHED
/* schedulable entities of this group on each cpu *///普通进程调度单元,之所以用调度单元,因为被调度的可能是一个进程,也可能是一组进程
struct sched_entity **se;
/* runqueue "owned" by this group on each cpu *///公平调度队列
struct cfs_rq **cfs_rq;
//下面就是如上示例的控制阀值
unsigned long shares;
atomic_t load_weight;
#endif
#ifdef CONFIG_RT_GROUP_SCHED
//实时进程调度单元
struct sched_rt_entity **rt_se;
//实时进程调度队列
struct rt_rq **rt_rq;
//实时进程占用CPU时间的带宽(或者说比例)
struct rt_bandwidth rt_bandwidth;
#endif
struct rcu_head rcu;
struct list_head list;
//task_group呈树状结构组织,有父节点,兄弟链表,孩子链表,内核里面的根节点是root_task_group
struct task_group *parent;
struct list_head siblings;
struct list_head children;
#ifdef CONFIG_SCHED_AUTOGROUP
struct autogroup *autogroup;
#endif
struct cfs_bandwidth cfs_bandwidth;
};调度单元有两种,即普通调度单元和实时进程调度单元。
struct sched_entity {
struct load_weightload;/* for load-balancing */struct rb_noderun_node;
struct list_headgroup_node;
unsigned inton_rq;
u64exec_start;
u64sum_exec_runtime;
u64vruntime;
u64prev_sum_exec_runtime;
u64nr_migrations;
#ifdef CONFIG_SCHEDSTATS
struct sched_statistics statistics;
#endif
#ifdef CONFIG_FAIR_GROUP_SCHED
//当前调度单元归属于某个父调度单元
struct sched_entity*parent;
/* rq on which this entity is (to be) queued: *///当前调度单元归属的父调度单元的调度队列,即当前调度单元插入的队列
struct cfs_rq*cfs_rq;
/* rq "owned" by this entity/group: *///当前调度单元的调度队列,即管理子调度单元的队列,如果调度单元是task_group,my_q才会有值
//如果当前调度单元是task,那么my_q自然为NULL
struct cfs_rq*my_q;
#endif
void *suse_kabi_padding;
};
struct sched_rt_entity {
struct list_head run_list;
unsigned long timeout;
unsigned int time_slice;
int nr_cpus_allowed;
struct sched_rt_entity *back;
#ifdef CONFIG_RT_GROUP_SCHED
//实时进程的管理和普通进程类似,下面三项意义参考普通进程
struct sched_rt_entity*parent;
/* rq on which this entity is (to be) queued: */struct rt_rq*rt_rq;
/* rq "owned" by this entity/group: */struct rt_rq*my_q;
#endif
};
下面看一下调度队列,因为实时调度和普通调度队列需要说明的选项差不多,以实时队列为例:
struct rt_rq {
struct rt_prio_array active;
unsigned long rt_nr_running;
#if defined CONFIG_SMP || defined CONFIG_RT_GROUP_SCHED
struct {
int curr; /* highest queued rt task prio */#ifdef CONFIG_SMP
int next; /* next highest */#endif
} highest_prio;
#endif
#ifdef CONFIG_SMP
unsigned long rt_nr_migratory;
unsigned long rt_nr_total;
int overloaded;
struct plist_head pushable_tasks;
#endif
//当前队列的实时调度是否受限
int rt_throttled;
//当前队列的累计运行时间
u64 rt_time;
//当前队列的最大运行时间
u64 rt_runtime;
/* Nests inside the rq lock: */raw_spinlock_t rt_runtime_lock;
#ifdef CONFIG_RT_GROUP_SCHED
unsigned long rt_nr_boosted;
//当前实时调度队列归属调度队列
struct rq *rq;
struct list_head leaf_rt_rq_list;
//当前实时调度队列归属的调度单元
struct task_group *tg;
#endif
};通过以上3个结构体分析,可以得到下图(点击看大图):
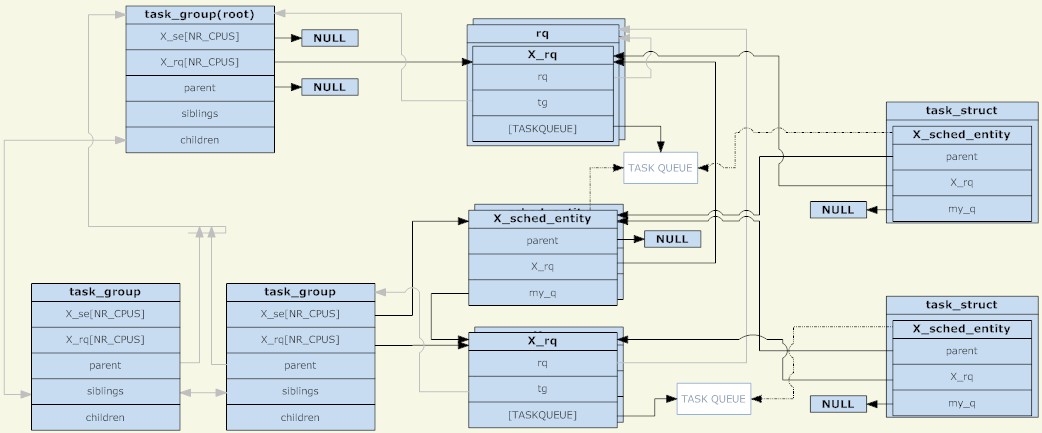
从图上可以看出,调度单元和调度队列组合一个树节点,又是另一种单独树结构存在,只是需要注意的是,只有调度单元里面有TASK_RUNNING的进程时,调度单元才会被放到调度队列中。
另外一点是,在没有组调度前,每个CPU上只有一个调度队列,当时可以理解成所有的进程在一个调度组里面,现在则是每个调度组在每个CPU上都有调度队列。在调度过程中,原来是系统选择一个进程运行,当前则是选择一个调度单元运行,调度发生时,schedule进程从root_task_group开始寻找由调度策略决定的调度单元,当调度单元是task_group,则进入task_group的运行队列选择一个合适的调度单元,最终找一个合适的task调度单元。整个过程就是树的遍历,拥有TASK_RUNNING进程的task_group是树的节点,task调度单元则是树的叶子。
组进程调度策略
组进程调度要实现的目的和原来没有区别,就是完成实时进程调度和普通进程调度,即rt和cfs调度。
CFS组调度策略:
文章前面示例中提到的任务分配CPU,说的就是cfs调度,对于CFS调度而言,调度单元和普通调度进程没有多大区别,调度单元由自己的调度优先级,而且不受调度进程的影响,每个task_group都有一个shares,share并非我们说的进程优先级,而是调度权重,这个是cfs调度管理的概念,但在cfs中最终体现到调度优先排序上。shares值默认都是相同的,所有没有设置权重的值,CPU都是按旧有的cfs管理分配的。总结的说,就是cfs组调度策略没变化。具体到cgroup的CPU控制机制上再说。
RT组调度策略:
实时进程的优先级是设置固定,调度器总是选择优先级最高的进程运行。而在组调度中,调度单元的优先级则是组内优先级最高的调度单元的优先级值,也就是说调度单元的优先级受子调度单元影响,如果一个进程进入了调度单元,那么它所有的父调度单元的调度队列都要重排。实际上我们看到的结果是,调度器总是选择优先级最高的实时进程调度,那么组调度对实时进程控制机制是怎么样的?
在前面的rt_rq实时进程运行队列里面提到rt_time和rt_runtime,一个是运行累计时间,一个是最大运行时间,当运行累计时间超过最大运行时间的时候,rt_throttled则被设置为1,见sched_rt_runtime_exceeded函数。
if (rt_rq->rt_time > runtime) {
rt_rq->rt_throttled = 1;
if (rt_rq_throttled(rt_rq)) {
sched_rt_rq_dequeue(rt_rq);
return 1;
}
}设置为1意味着实时队列中被限制了,如__enqueue_rt_entity函数,不能入队。
static inline int rt_rq_throttled(struct rt_rq *rt_rq)
{
return rt_rq->rt_throttled && !rt_rq->rt_nr_boosted;
}
static void __enqueue_rt_entity(struct sched_rt_entity *rt_se, bool head)
{
/*
* Don't enqueue the group if its throttled, or when empty.
* The latter is a consequence of the former when a child group
* get throttled and the current group doesn't have any other
* active members.
*/if (group_rq && (rt_rq_throttled(group_rq) || !group_rq->rt_nr_running))
return;
.....
}
其实还有一个隐藏的时间概念,即sched_rt_period_us,意味着sched_rt_period_us时间内,实时进程可以占用CPU rt_runtime时间,如果实时进程每个时间周期内都没有调度,则在do_sched_rt_period_timer定时器函数中将rt_time减去一个周期,然后比较rt_runtime,恢复rt_throttled。
//overrun来自对周期时间定时器误差的校正
rt_rq->rt_time -= min(rt_rq->rt_time, overrun*runtime);
if (rt_rq->rt_throttled && rt_rq->rt_time < runtime) {
rt_rq->rt_throttled = 0;
enqueue = 1;
则对于cgroup控制实时进程的占用比则是通过rt_runtime实现的,对于root_task_group,也即是所有进程在一个cgroup下,则是通过/proc/sys/kernel/sched_rt_period_us和/proc/sys/kernel/sched_rt_runtime_us接口设置的,默认值是1s和0.95s。这么看以为实时进程只能占用95%CPU,那么实时进程占用CPU100%导致进程挂死的问题怎么出现了?
原来实时进程所在的CPU占用超时了,实时进程的rt_runtime可以向别的cpu借用,将其他CPU剩余的rt_runtime-rt_time的值借过来,如此rt_time可以最大等于rt_runtime,造成事实上的单核CPU达到100%。这样做的目的自然规避了实时进程缺少CPU时间而向其他核迁移的成本,未绑核的普通进程自然也可以迁移其他CPU上,不会得不到调度,当然绑核进程仍然是个杯具。
static int do_balance_runtime(struct rt_rq *rt_rq)
{
struct rt_bandwidth *rt_b = sched_rt_bandwidth(rt_rq);
struct root_domain *rd = cpu_rq(smp_processor_id())->rd;
int i, weight, more = 0;
u64 rt_period;
weight = cpumask_weight(rd->span);
raw_spin_lock(&rt_b->rt_runtime_lock);
rt_period = ktime_to_ns(rt_b->rt_period);
for_each_cpu(i, rd->span) {
struct rt_rq *iter = sched_rt_period_rt_rq(rt_b, i);
s64 diff;
if (iter == rt_rq)
continue;
raw_spin_lock(&iter->rt_runtime_lock);
/*
* Either all rqs have inf runtime and there's nothing to steal
* or __disable_runtime() below sets a specific rq to inf to
* indicate its been disabled and disalow stealing.
*/if (iter->rt_runtime == RUNTIME_INF)
goto next;
/*
* From runqueues with spare time, take 1/n part of their
* spare time, but no more than our period.
*/diff = iter->rt_runtime - iter->rt_time;
if (diff > 0) {
diff = div_u64((u64)diff, weight);
if (rt_rq->rt_runtime + diff > rt_period)
diff = rt_period - rt_rq->rt_runtime;
iter->rt_runtime -= diff;
rt_rq->rt_runtime += diff;
more = 1;
if (rt_rq->rt_runtime == rt_period) {
raw_spin_unlock(&iter->rt_runtime_lock);
break;
}
}
next:
raw_spin_unlock(&iter->rt_runtime_lock);
}
raw_spin_unlock(&rt_b->rt_runtime_lock);
return more;
}
先写到这里,未完待续。
参考资料:
http://hi.baidu.com/_kouu/item/0fe32610e493314be75e06d1
Linux进程组调度机制分析来自于OenHan
链接为:https://oenhan.com/task-group-sched
“schedule进程从root_task_group开始寻找由调度策略决定的调度单元”
schedule程序不是直接从每个rq中的来寻找调度实体吗,怎么会是从root_task_group来寻找呢?