决策树与ID3算法
在机器学习和数据挖掘领域里,决策树是一种有效的归纳推理算法之一,它将训练样本抽象出多个特征函数,通过离散值的函数输出归纳成一个决策树,由于是有训练样本统计而来,它对样本噪声有一定的健壮性。
一、什么是决策树
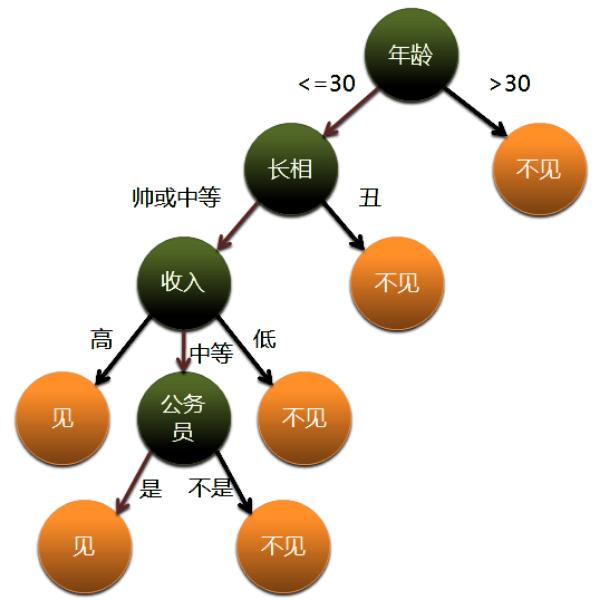
直接看图说话: 一个母亲给女儿介绍相亲对象,女孩见不见呢?(图片剽窃自CodingLabs)
女孩根据自己的一系列条件进行判定相亲对象见面与否,决策树就是根据训练样本构造出一个条件判断多叉树,最终使测试用例在决策树中获取一个最优值。 通过上面可以看出,进入决策树中的特征用例都是由“属性-属性值”的方式出现的,而且作为节点的函数的输出值必须是离散值。
二、构建决策树
决策树是一层层构建的,在每一层就要选择一个属性根据它的属性值进行分裂,先选择那个属性进行分裂是决策树构建需要解决的主要问题。数据在决策树中的流动最终会指向一个目的,成为一个有序的集合,那么最先进行分裂的应是分裂后无序性最大降低的属性,就是ID3算法。 信息熵:根据高中的化学知识,熵表示一个物质的混乱程序,均匀无序的值为1,完全有序则值为0,信息越有序则信息量越小(100GB磁盘数据全为1,信息就一个位),信息越混乱,则信息量越大,信息熵是信息论中用于度量信息量的一个概念。 计算公式:

信息增益:将样本的所有属性分割开,分别计算,熵之和

信息增益就是二者的差值
如果我们有以下样本:
| 年龄小 | 长相好 | 收入高 | 公务员 | 见面 |
| 1 | 0 | 1 | 1 | 0 |
| 1 | 1 | 1 | 1 | 1 |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 1 | 0 | 0 |
| 0 | 0 | 1 | 0 | 1 |
| 1 | 1 | 1 | 0 | 0 |
| 1 | 1 | 0 | 1 | 1 |
注意:表格数据纯属编造
info(D)=(-(3/7)log(3/7)-(4/7)log(4/7))/log2=0.985
info(年龄)(D)=((3/7)*(-(1/3)*log(1/3)-(2/3)*log(2/3))+(4/7)*(-0.5*log0.5-0.5log0.5))/log2=0.965
数据计算写成如上格式只是方便通过谷歌计算

则年龄小的因素的信息增益则为:
gain(年龄)
=info(D)-info(年龄)(D)
=0.985-0.965=0.02
同理gain(长相)=0.02;
gain(收入)=0.0057;
gain(公务员)=0.128;
如此我们看到是公务员因素增益最高
那我们就应该先前的决策树的第一个决策因子变为“是否是公务员”,而非“年龄”,而通过虚构的数据样本看,相亲里面最重要的因素是“是否是公务员”。
将公务员因子分裂之后,所有样本分成两部分,则分别对这两个部分进行决策树构造,分裂因子,直到所有因子全部被分裂,就构成了一个决策树。
三、C4.5算法
ID3算法有一个缺点:决策分裂取向倾向于多属性的值。这原本是它的优势:单属性的值分裂没有意义。但过多的强调多属性也有一些问题,如相亲的时候引入日期的参数,基本上一个日期因子的值都会决定了最终结果,(主要是日期因子的值远超过决策树结果的值),ID3算法就会优选分裂日期因子,很明显这是没有意义的。
那么,就不能选择信息增益作为分裂因子选择的参数,新的度量标准是“增益比率”。
增益比率是通过增加了一个叫做“分裂信息”的参数,来惩罚类似日期的多属性的因子。

增益比率:

增益比率事实上限制了选择值为均匀分布的属性。
决策树与ID3算法来自于OenHan
链接为:https://oenhan.com/decision-tree-id3